Introduction
The notion of an index has become such a staple in traditional and modern data engineering that it’s very important to grasp the basic concepts. All SQL engines use indexes for the same reason, speed and consistency and almost all of them use some form of a clustered and non-clustered index.
We understand this concept if we think of a table in SQL as a library and think of how librarians might try to resolve similar problems. In this example a book would be the equivalent of a record in this table with column names like “Title”, “Year of release”, “Author”, “Category” etc. Additionally, let’s think that our library infrastructure has been completed and it is ready to receive all the great books of the world.
The first order of business would be of course, how we could physically arrange the books in the bookshelves.
Clustered indexes - The librarian’s dilemma
“Let’s sort them alphabetically by title and author.” says the first librarian, “That way when we get asked for a specific book title, we can easily track it down.”
“Good thinking,” says the second librarian, “but that way, it would be extremely hard to find all books of a specific topic.”
“How about we order them as they come, the first received book would be first on the shelves, second would be right behind it etc.” says a new colleague of the librarians.
“And how are we going to make sense of the chaos we created?” asked puzzlingly the second librarian.
“I have already started placing books on the shelves, so unless you want to be ignored when I ask what kind of pizza we are getting for lunch, I suggest you follow my lead” decreed the chief librarian.
“I see,” said the second librarian, “we are first splitting them by category and then placing them alphabetically!”
The conversation above, correlates to critical decisions when for SQL code and logic. All three cases mentioned are examples of a clustered index. So, in essence, a clustered index is a physical representation of the way an SQL engine sorts the records in the hard drives. It is obvious that a table can have only one clustered index. Most SQL engines assign a clustered index on table creation.
Let’s dig in deeper:
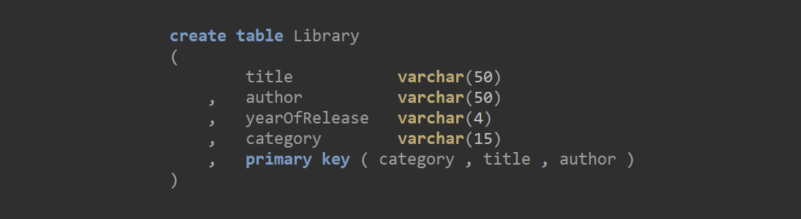
The first librarian’s suggestion would be a clustered index on both the book title and author, so:

The new colleague’s idea would be a clustered index on an auto-incrementing integer:
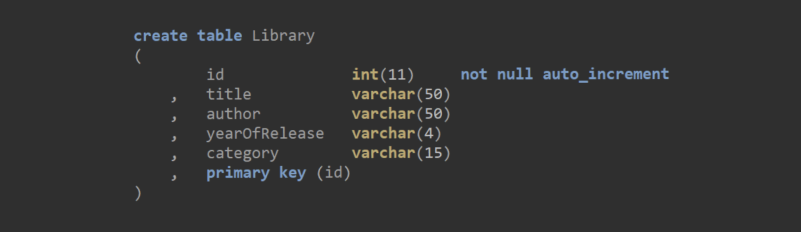
And finally, the chief librarian’s pizza-induced “suggestion” would be a clustered index on category, title and then author:
Non-Clustered Indexes
“And what about if I wanted a list of all books that were released in 2003,” said the janitor “or all the books written by Tolkien. How would you find those?”, now lowering his voice “without having to shift through them one by one…”
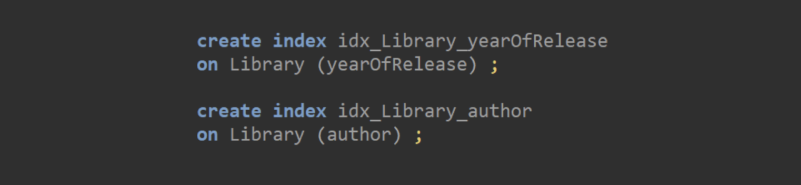
“Ahh, great question! We could make special lists to pinpoint the location of each inquiry you just mentioned!”, replied the second librarian. “So, for example, we can have an… index where each author is listed alphabetically and next to his name have all the bookshelf positions of his books.”
Following the logic above, we can say that non-clustered indexes are separate entities where one or more columns point to the appropriate records. Unlike a clustered index, there’s nothing stopping us from having more than one non-clustered indexes for the same table. There are of course some downsides to using non-clustered indexes. The two biggest are that these take additional storage and it makes inserting, updating and deleting records slower.
If we wanted to represent them in code then the example below does exactly that:
Conclusion
By examining this simple example of a library sorting and organizing their books, we can understand the concept of indexes in a real-life scenario.
A clustered index is a unique property of a table and it affects the physical distribution of data on the hard drive. It has no impact on how an SQL engine can insert/update/delete records in that table. Nor does it impact storage by any way.
A non-clustered index is not unique, we can have as many as possible in a table. It impacts both write speeds and storage!
Both of their purposes are to increase speed by which we can retrieve data from an SQL engine. And in that regard both of them are mighty helpful! But we have to use non-clustered indexes in moderation, since having too many of them could hinder write performance and impact storage negatively.
If we wanted to do a graph of the above pros and cons:
| Clustered index | Non-clustered index | |
|---|---|---|
| Unique | ||
| Impact on write speeds | ||
| Additional storage needed |
The biggest takeaway would be that clustered indexes and non-clustered indexes are not rivals but partners! A clustered index would, most of the time, be the star of the show, with the non-clustered indexes being the much needed support.