Introduction
In this article, we'll provide an intuitive and high-level
understanding of image generation using deep generative
modeling. We'll introduce two popular models, Generative
Adversarial Networks (GANs) and Diffusion Models (DMs), and
explain their differences. While GANs have been around for
nearly a decade and have monopolized the majority of image
generation workloads, a new breed of generative models, i.e.
diffusion models, threaten to overthrow GANs’ dominance. DMs
have recently managed to produce a lot of hype in both
tech/academic communities as well as mainstream media, as they
have constituted the backbone of several recent AI-powered
text-to-image breakthroughs such as
GLIDE [1],
Imagen [2],
DALLE-2 [3],
Stable [4], or even text-to-video and text-to-3D, like
Make-A-Video [5]
and
DreamFusion [6]. With this in mind, we’ll use the rest of the current article
as an opportunity to dive deeper into DMs, including theoretical
foundations and practical examples, with emphasis laid on
image-based expression swapping (a.k.a. face reenactment).
Get ready to explore the exciting world of generative modeling!
Let's start with the basics: GANs vs Diffusion Models
One of the most intriguing computational tools—one that tests human creativity—is deep generative modeling. Due to their ability to generate high-quality samples, Generative Adversarial Networks (GANs) have drawn a lot of attention in the last ten years. Diffusion models, a more recent generative technique that is even more potent than GANs, pose a threat to GANs' dominance in the generation of synthetic data.
GANs
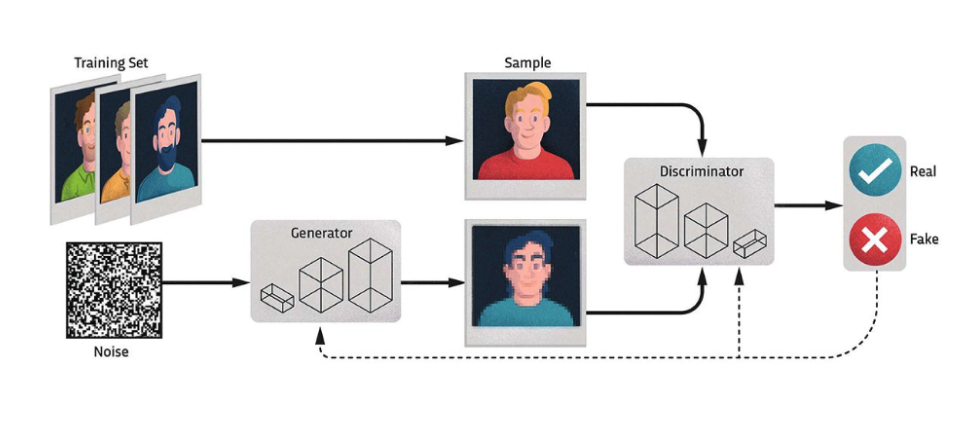
Before moving onto diffusion models, let’s take a brief moment to understand how GANs generally operate. GANs, as introduced by Goodfellow et al. [7] represent a zero-sum game between two machine players, a generator and a discriminator, designed to learn the distribution of a given set of images. As seen in Fig. 1, the generator tries to produce truthful samples out of pure noise, while the discriminator tries to identify which images are real and which are fake. The goal of the generator is to trick the discriminator into believing that these synthetic images are actually real.
Diffusion Models
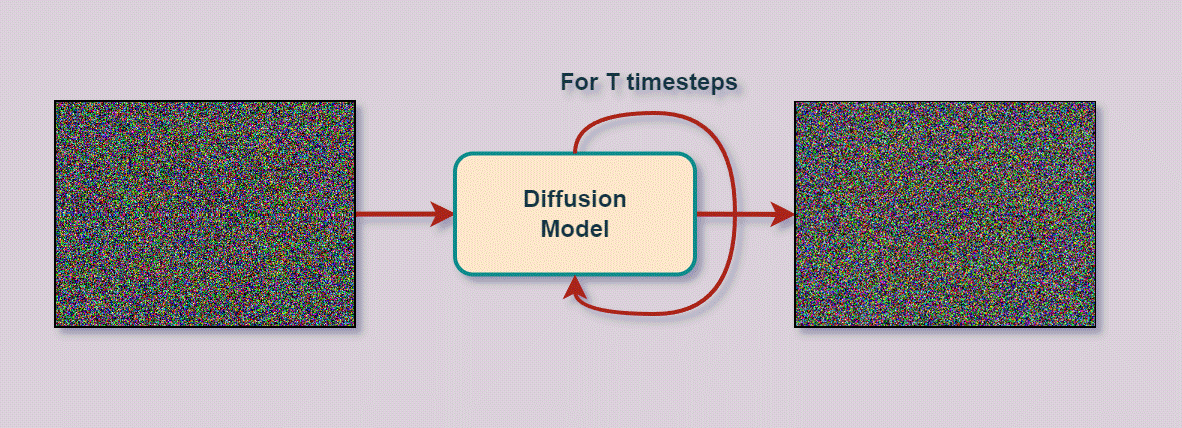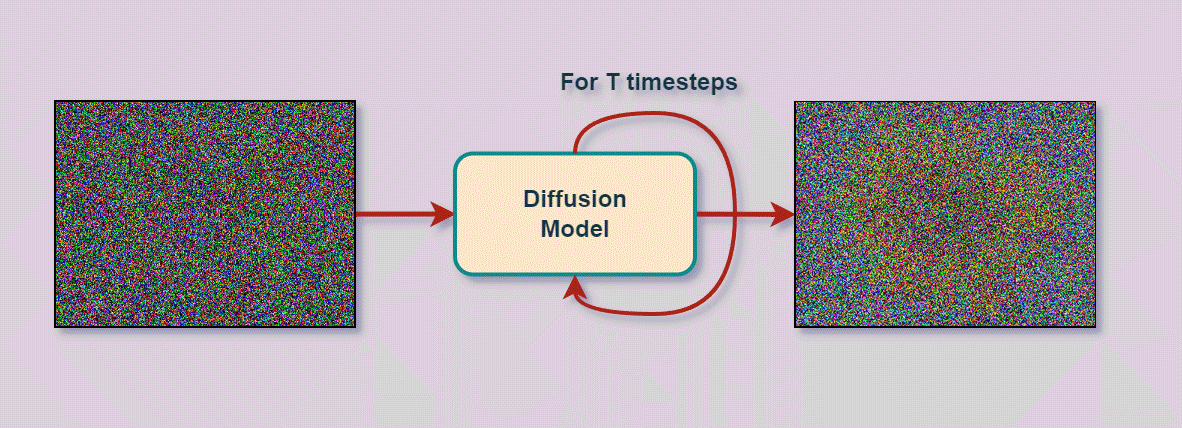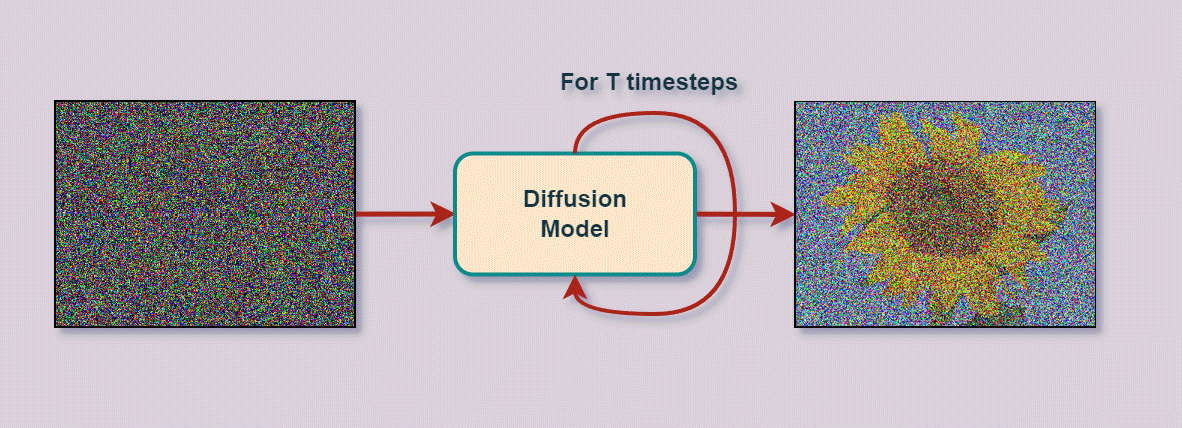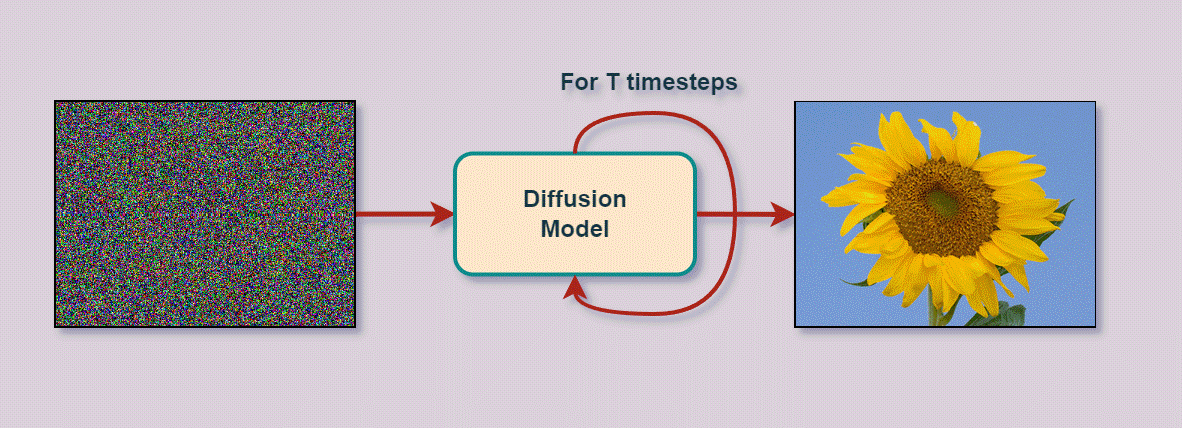
Let’s move to diffusion, but first it makes sense to introduce the notion itself. Sohl-Dickstein et al. [8] in their seminal work, drew inspiration from the field of thermodynamics, where the term ‘diffusion’ refers to the flow of particles from high density regions towards low density ones. From a statistical point of view, diffusion refers to the process of transforming a complex, high dimensional distribution into a simpler, predefined prior (e.g. Standard Normal), in the same domain. Denoising diffusion probabilistic models (DDPM) [9], i.e. the discrete-time variant of DMs, tackle the image generation task through a different approach, compared to GANs.
A DDPM is composed of two opposite processes, a (forward) diffusion process and a (reverse) sampling process, as illustrated in Fig. 2. Each of the aforementioned processes is (in the discrete-time case) parameterized by a Markov chain. The forward process first gradually perturbs images by applying small amounts of Gaussian noise, for a predefined number of diffusion steps, until any initial image structure is lost. In the sampling process, a deep convolutional neural network (CNN) tries to denoise the perturbed, noisy images by either predicting the original image (given the noisy one) or by predicting the amount of noise added at each pixel location of the original image. Given enough training data and epochs, the two aforementioned processes, when combined, result in a generative model that has essentially learned the underlying image distribution and can produce synthetic images out of pure noise. The diffusion process can also be extended to infinitely many time-steps (or equivalently noise scales) where both the continuous time diffusion and sampling processes are represented in terms of stochastic differential equations, as proposed by Song et al. [10]. However, the continuous-time case exceeds the scope of the current article.
Comparison: Pros and Cons
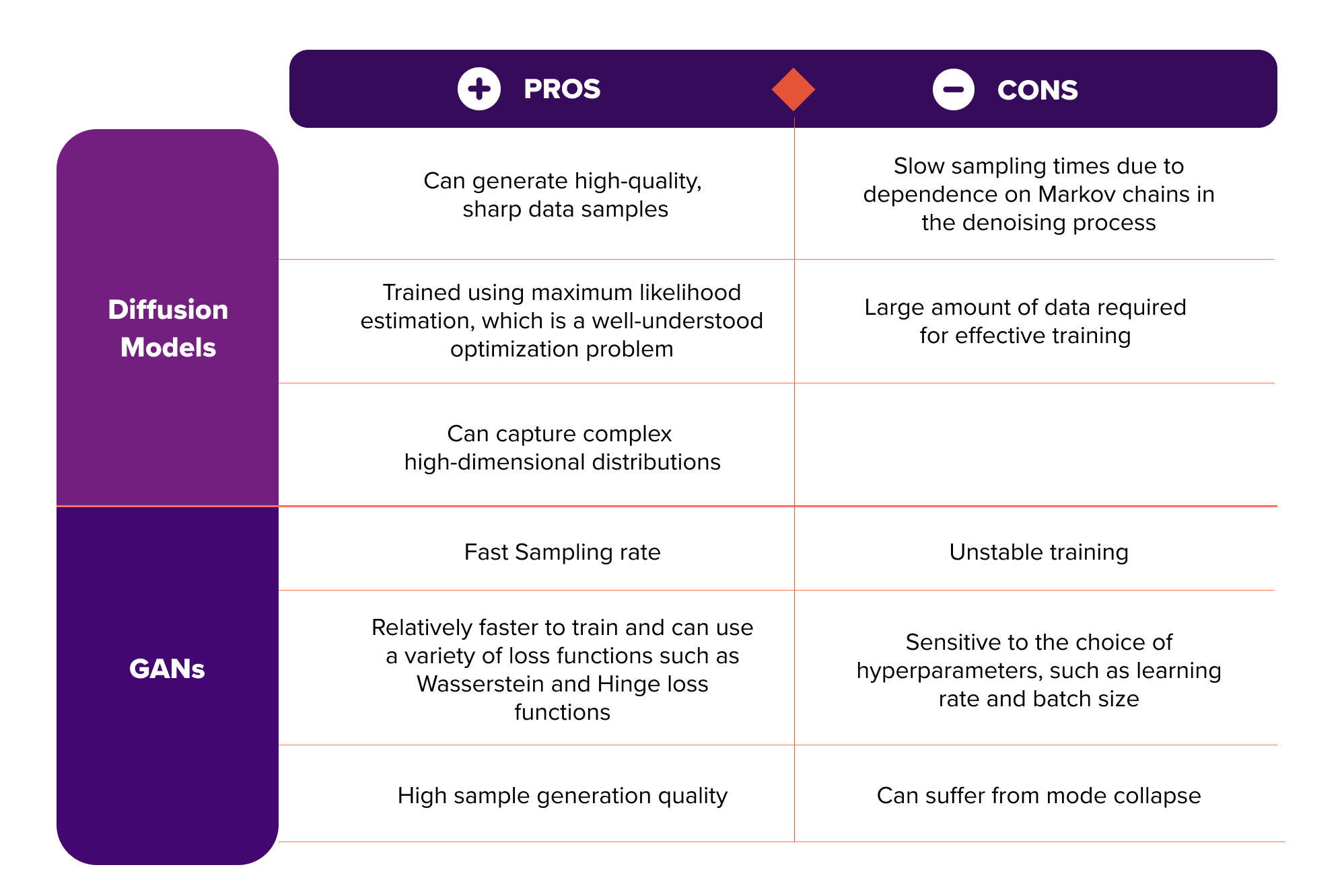
Having given a brief overview of both GANs and diffusion models, it’s time to discuss the pros and cons of the latter. Diffusion models are both analytically tractable and flexible, i.e. they can cheaply fit data (e.g. through a Gaussian), they support analytical evaluation and can easily describe rich, high-dimensional data structures. On the other hand, diffusion models rely on a long Markov chain of diffusion steps to generate samples, so it can be quite expensive in terms of time and computational resources. New methods have been proposed to make the process much faster, but the sampling is still slower than GANs. Tab. 1 summarizes the main key points regarding the advantages and disadvantages of using diffusion models in comparison with GANs.
Deepfakes and Facial Manipulations
After this “brief” but hopefully informative introduction, it’s time to dive right into the more practical aspect of generative modeling and diffusion models. Recent years have seen a significant increase in the public's concern over fake images and videos that include facial data produced by digital manipulation, particularly with Deepfake methods. A deep learning-based technique, known as Deepfake, can produce fake videos by replacing one person's face with the face of another person. This phrase first appeared after a Reddit user going by the name of ‘deepfakes’ claimed to have created a machine learning algorithm that enabled him to insert faces of famous people into pornographic videos, in late 2017. Deepfakes fall under the category of identity swapping techniques, which in turn are considered as a specific case of facial manipulations. Apart from identity swapping, facial manipulations also include (entire) face synthesis, facial attribute manipulation and expression swapping. For the demonstration purposes of this article, we decided to dedicate the following paragraphs to the use-case of image-based facial expression manipulation, also known as face reenactment. Let's take a first look at Fig. 3, where we provide some examples of face reenactment with happiness being the target emotion.

Expression Swapping with DMs
The first step towards a facial expression manipulation experimental setup, is the collection of real data samples. For this reason, Satori conducted an internal crowdsourcing initiative in which company employees volunteered to provide photos of themselves while maintaining different facial expressions (including neutral).
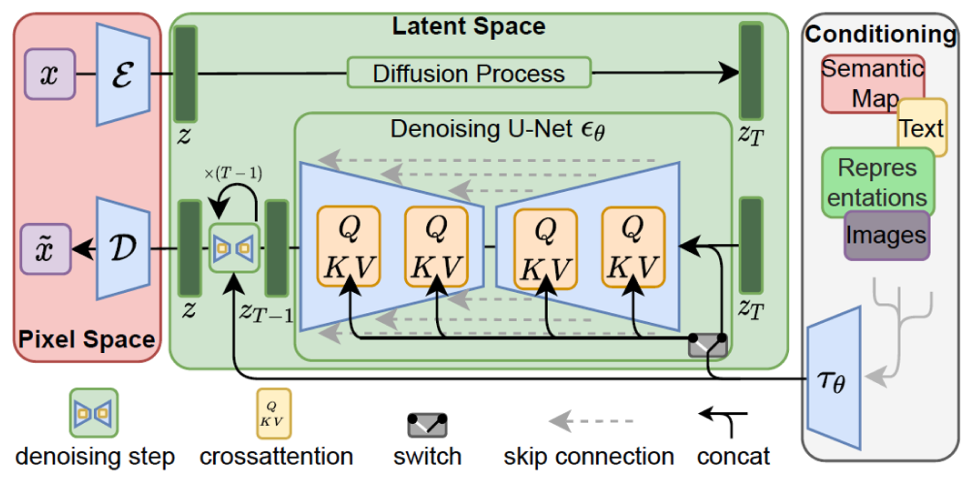
After data collection, images underwent face cropping and alignment using a deep learning-based face detector. In terms of the generation process, we utilized a Latent Diffusion Model (LDM) [4] which constitutes a more lightweight variant of the vanilla DDPM which operates on a learnt, lower dimensional latent space rather than the original, high-dimensional and compute-intensive pixel space, with the help of an additional encoder-decoder module. An overview of the LDM framework can be seen in Fig. 4. The neural network backbone features a U-Net [11] architecture. The LDM was trained on the AffectNet database, as introduced by Mollahosseini et al. [12] which is by far the largest database of facial expressions that provides both categorical [13] and dimensional [14] annotations based on the valence-arousal space.
In order to put diffusion models to the test, we formulated the following task: Given an original employee face image, we want to manipulate their facial expressions as faithfully as possible, relative to the six basic emotions:
- Happiness,
- Sadness,
- Surprise,
- Fear,
- Disgust, and
- Anger
At the same time, our ambition is to preserve their identity-specific facial attributes and characteristics.
Done with the talking. Time to deliver!
Without going into much detail, the manipulation process involves the application of a forward and backward (in time) ordinary differential equation, conditioned on the original and target emotion, respectively. The processes involved during image manipulation run in a deterministic manner and are based on the Denoising Diffusion Implicit models (DDIM), as introduced by Song et al [15].
In Fig. 5 we present curated samples obtained using the aforementioned methodology, across all the six target emotions.

As we can see, the generated images look sharp, artifact-free, faithful to the original subject while achieving relatively accurate emotion transfer with the exception of semantically similar emotions. Examples of this can be seen in the third row of the above figure, where there is a slight but noticeable difference between the emotions of surprise and fear, as well as between anger and disgust.
Still got work to do!
Even though the above samples look convincing, we must not be misled into believing that one single diffusion model can provide a global solution to the facial emotion manipulation task. Performance is strongly dependent on both data-related and model parameter-related issues. We need to remind ourselves that diffusion models, as any other generative model, learn the data distribution of the provided training set, while during manipulation, the model is asked to decouple identity specific characteristics from emotion-related ones, with the aim of generalizing to unseen images. When the training data distribution differs from the actual evaluation image set, we can end up with absurd results. Moreover, the manipulation process is extremely sensitive to the amount of initial added noise, i.e. the number of diffusion steps used during the forward/noising process. Controlling the amount of added noise enables the production of a wide variety of results but is tricky in general and if not done properly can lead to complete loss of the original subject identity, like the following fail-cases of Fig. 6:

Also, we need to keep in mind that the current model has been trained using limited resources and the above fail-cases should, in no way, imply any kind of inherent architectural flaw relative to DMs.
To Sum-up
As discussed above, DMs can generate high-quality images and provide fine-grained control over the generative process, allowing for smooth and coherent image generation. However, they can be computationally expensive and require a large amount of data to train. In contrast, GANs are faster to train and require less data but may struggle with generating high-resolution images or have mode collapse issues. DMs appear to have more potential than GANs, which is the primary driver behind the academic community's race to offer solutions to some of their aforementioned shortcomings. However, given their growing popularity and the current trend of democratizing AI, we ought to remember that great power should always come with great responsibility and that the use of any AI-powered generative model must always be accompanied with clear ethical guidance in mind.
References:
[1] Nichol, A.Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin,
P., Mcgrew, B., Sutskever, I., Chen, M. (2022). GLIDE: Towards
Photorealistic Image Generation and Editing with Text-Guided
Diffusion Models. In Proc. International Conference on Machine
Learning (ICML).
[2] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J.,
Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan,
B., Salimans, T., Ho, J., Fleet, D.J., Norouzi, M. (2022).
Photorealistic text-to-image diffusion models with deep language
understanding. Advances in Neural Information Processing Systems
(NeurIPS), 35, 36479-36494.
[3] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M.
(2022). Hierarchical text-conditional image generation with CLIP
latents. arXiv preprint arXiv:2204.06125.
[4] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer,
B. (2022). High-resolution image synthesis with latent diffusion
models. In Proc. IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR), 10684-10695.
[5] Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang,
S., Hu, Q., Yang, H., Ashual, O., Gafni, O. and Parikh, D.,
Gupta, S., Taigman, Y. (2023). Make-A-Video: Text-to-video
generation without text-video data. In Proc. International
Conference of Learning Representations (ICLR).
[6] Poole, B., Jain, A., Barron, J. T., & Mildenhall, B. (2023).
Dreamfusion: Text-to-3D using 2D diffusion. In Proc.
International Conference of Learning Representations (ICLR).
[7] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y.
(2020). Generative adversarial networks. Communications of the
ACM, 63(11), 139-144.
[8] Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., &
Ganguli, S. (2015). Deep unsupervised learning using
nonequilibrium thermodynamics. In Proc. International Conference
on Machine Learning (ICML).
[9] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion
probabilistic models. Advances in Neural Information Processing
Systems (NeurIPS), 33, 6840-6851.
[10] Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A.,
Ermon, S., & Poole, B. (2021). Score-based generative modeling
through stochastic differential equations. In Proc.
International Conference of Learning Representations (ICLR).
[11] Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net:
Convolutional networks for biomedical image segmentation. In
Proc. Medical Image Computing and Computer-Assisted
Intervention–MICCAI 2015, 234-241.
[12] Mollahosseini, A., Hasani, B., & Mahoor, M. H. (2017).
Affectnet: A database for facial expression, valence, and
arousal computing in the wild. IEEE Transactions on Affective
Computing, 10(1), 18-31.
[13] Ekman, P., & Friesen, W. V. (1978). Facial action coding
system. Environmental Psychology & Nonverbal Behavior.
[14] Russell, J. A., & Mehrabian, A. (1977). Evidence for a
three-factor theory of emotions. Journal of Research in
Personality, 11(3), 273-294.
[15] Song, J., Meng, C., & Ermon, S. (2021). Denoising diffusion
implicit models. In Proc. International Conference of Learning
Representations (ICLR).